HIGH SPEED DATA STORE FOR NETWORK/TELECOM ELEMENTS
WE ARE ACTIVELY LOOKING FOR PARTICIPANTS. WE NEED SKILLSET IN AREAS LIKE DESIGN, ARCHITECTURE,
PROGRAMMING ( C++), LANGUAGE DESIGN , CODE GENERATION.
Introduction:
Data
store aims to provide a high speed database for storing the operational
state of a system. System can be any networking device a router , switch etc. Data store uses the "network database model"
which helps to model the schema close to the object model of the
system. Data store introduces new abstractions to program with and a
schema language closely modelled on "object definition language".
System state of a Network element:
System
state is the current
state of a network/telecommunication element. System state of any
networking device can
be expressed in terms of objects and the relationships among them. System state is of
read-often and write-rare nature. Software can access this data to do
lookups and on do operations on a per packet basis. Data store allows
efficient and storage and high speed retrieval of this system state, it also
allows composing relationships dynamically among different objects in the system at run time.
if we take the case of a networking router/switch the data store
can be used to store objects like ports, subinterfaces, channels ,
addresses , routes, next hops etc. In all the succeeding sections we
will take the case of a network router to explain the concepts of
datastore.
Problem with existing representations of system state:
Most
of the systems store the
state inside kernel. In this model the state is replicated across
multiple daemons for their operation. The main problem with this
approach is muliple copies of same data floating which
results in high wastage of memory. Keeping multiple copies of same data
also leads to coherency problem. This coherency problem can be solved
by sending notifications to all the daemons to make sure all the
daemons are seeing the same picture. Every time the state is change it
needs to be updated in all the daemons which includes unnecessary IPC
and system call context switches in system.
Some
advanced systems use a
high speed sql database. The main problem with this approach is the
impedance mismatch between the programming language and the sql query
language. Daemon writers need to
understand the sql schema to access the data base. Data is accessed
through complex sql queries which imposes certain latency on the
database operations limiting the through put of the device. The
application software is plagued with sql query statements all over.
Data store Abstractions:
Data store introduces new abstractions to program with, software
developers who intend to use the data store need to understand
these abstractions to write effective code.
Class:
Class is similar in meaning to the one used in object oriented programming languages.
Relationship:
A relation ship is the relation between
2 classes. Relationships are hooks through which objects connect with
each other.
Method:
A method is a member function defined
in the class and can be called after instantiating the objects of the
class with an object reference.
Transaction:
A transaction is an atomic
operation which involves changes on multiple objects. Transaction
ensures either all the changes on all the objects are applied or none
of them are applied.
Multiple operations on the data
store can be batched in to a transaction and issued on data store
either all of them are applied or none.
Facilities offered by Data store:
- High
speed read access
with a performance nearly equal to local memory read. Using memory
mapping techniques the object is made available to the applications as
a local memory variable.
- Transactional
semantics for
writes. Writes are a bit costly and result in one or more IPC messages.
Depending on the properties of the object a write operation can spawn a
transaction. Transaction can impose significant delays depending on the
number of resource managers participating in the commit protocol
(participants can be on same or different node).
- Facilities
to compose
objects in to relationships. Data store allows the objects to be
composed in to different kinds of relationships, relationships between
objects can change at run time. This facility brings significant
advantages allowing things like configuration processors to be
implemented.
- Objects can
participate in more than one relationships with different
objects in the system. Data store will provide API's to compose
relationships among objects. A relationship change can also spawn
transactions requiring the consensus between different daemons.
- Provides
near consistent
persistence. Some of the daemons in the system need persistent store to
save state. This state may be saved to avoid re-learning. A
nearly consistent persistence model is provided
to reduce the write latency in the system. Instead of writing the
object immediatly to the persistent storage, data store will write the
objects to persistent store on a periodic basis, this will reduce the
latency of the write operations on the data store objects.
- Consolidating
the state at a single place brings down the virtual memory requirement
of the network element. This in turn boosts up the performance of the
device.
- Simplifies the application development, data store will reduce the burden of maintaining the state
in the application by moving it to data store. Applications can concentrate more
on it's core functionality.
- Class based, object based, relationship based notifications to interested parties when some thing of interest happens.
- No need to learn
any new query languages to use the data store. Applications can use the
programming language data types and APIs to access and modify the
objects stored in data store.
Architecture of data store:
TBD.
Data store object:
Any data item which is stored
in the data store is a data object. Objects which are of global
interest should only be stored in data store. Object types should be
known at compile time for the data
store to recognize the object. API's are provided for creation /
deletion / get / set operations on the objects. Every time a new object
type is added to the data store we need to add its definition in a class defintion file and compile the object plugin again.
Operations on the data store objects:
Add Operation:
An add operation results in addition of an
object to the data store. This operation sends class based
notifications to interested parties. Class based notifications will be
discussed in
later sections.
An add operation involves generation of one or more interprocess communication
messages. Occasionally an add operation might spawn a costly
transaction depending on
the object properties. Transactions are discussed in later sections.
Delete Operation:
A Delete operation results in deletion of an object
from the data store. This operation sends class based notification to
interested parties. Delete operation involves one or more inter
process communication messages. Occasionally a delete operation might
spawn a costly transaction depending on the object properties.
Transactions are discussed in later sections.
Read operation:
A read operation is used by the daemon to read a value of a particular
object. A read operation does not involve any interprocess
communication of any kind. A reference to the object is
obtained first and then the
reference is used to read the fields of the object. This is in the
order of direct memory reference.
Write operation:
A write operation results in modification of one of the attributes of
an object stored in data store. Write operation might send object based
notifications to interested parties. It might also
spawn a transaction depending on the properties of the object.
Relationships and composibility:
An object in isolation is of
little use. Objects in a system are realted to other objects by a
relationship. Depending on the complexity of the system an object can
participate with other objects in
more than one relationship. Data store provides facilities to compose
relationships between objects. Data store allows the programmer to
define more powerful relationships among the objects
as it uses the programming language constructs with out defining any
new languages. There are both static and dynamic aspects of a
relationship between 2 objects , these are described below.
Static aspects of a relationship:
Relation
ships are known at design time and are incorporated in the information
model. A class defines all the possible relation ship hooks that an
object can participate in at the time of
schema definition.
Dynamic aspects of a relationship:
Relation
ship hooks are instantiated and become valid when an object
participates in a relation ship with other objects at run time.
Relationship methods:
Objects
can be composed in to relationships with other objects in data store.
Every relationship will support 2 methods "compose" and "decompose". A
compose operation will typically add
the participant object in to a collection and a
decompose operation will remove the object from the collection.
Examples of few relationships in the system:
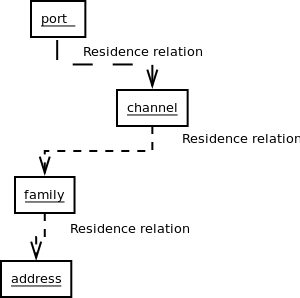
An
channel can reside on a port
and therefore we can say port and channel are related to each other by
"residence" relation. port is hosting the channel and channel is
residing on the port, therefore these 2 objects are bound together in
system by a named relationship called "residence_relation".
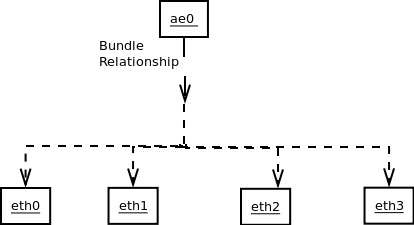
If we take the case of an
aggregated trunk in the system , an aggreagated bundle like ae0
has other ethernet ports in the system as its member links. therefore we can
define a relation between member links and the bundle as "bundle_relation".
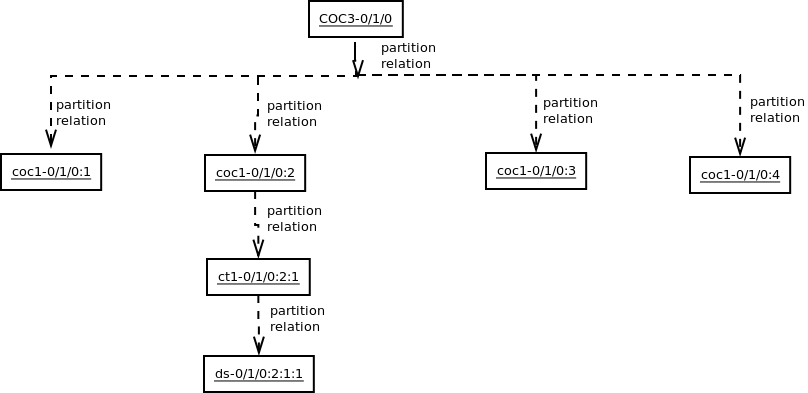
The partition layout of the
channelized ports can also be modelled in terms of relationships
like below, a relation called "partition_relation" can be defined to relate the
partition and base interface like below.
Addressing of objects in data store:
Addressing
is an important
aspect of the system and very much impacts the performance of the data
access. Every object in the datastore needs to be identified on its own
and not in relation or hierarchy its participating in. This imposes
some challenges on the datastore. For now every object is identified
with a plain string. Data store needs the type information along
with the address string to quickly fetch the objects.
Inter object transactions:
Some
times it's required to manipulate multiple objects in one shot.
Applications needs facilities to compose multiple operations on
multiple/same object in to one transaction. If the transaction succeeds
all the changes are succesfully applied else none of the objects gets
modified. Data store provides facilities to compose multiple operations
in to one transaction. Transactions are pretty costly in nature and
should be used sparingly.
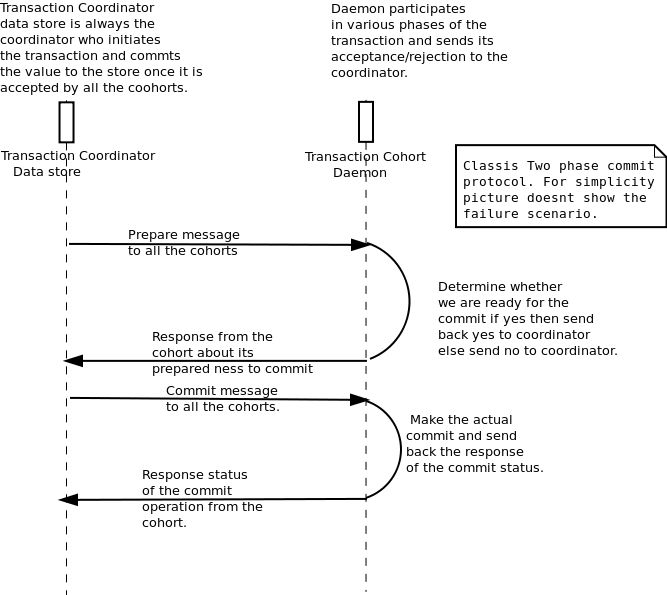
Distributed commit:
A
commit protocol is required if there are multiple parties interested in
validating the change on the object. They can reside on the same node
as well as different nodes in the system. Depending on the object
properties a commit protocol is started to seek the approval of the
change on the object. If all the parties approve the change on
the object then only the object is modified in the data
store. A 2 phase commit protocol is used to implement this
facility. Daemons/Applications should provide callbacks to the
datastore library to be executed in different phases of the commit
protocol.
An illustration of the two
phase commit protocol is given below, this is just for the illustration
purpose and not the actual protocol used.
Notifications:
A data store needs to
notify interested applications when some thing changes in it. Change
might
be at object level or at a class level or at a relationship level.
Notifications should be sparingly used as they can bring down the
system to a grinding halt on high loads.
Class level notification:
A class level notification
goes to interested parties when an object of a particular class is
created/deleted in the data store. Class level notifications carry a
duplicate of object deleted/added as a payload along with them.
Object level notification:
An object level notification
goes to interested parties when an object is modified. A duplicate of
the object modified is sent in the payload along with the notification.
Relationship based notification:
Relationship based
notifications are sent to applications when an object changes its
relationship with other objects.
Constraints and validation:
Constraints are checked before the operations on the datastore.
constraints can execute in the context of the datastore daemon or in
the context of the applications. Constraints executed
in the data store context can be inlined with the class definitions in
the schema file. Constraints executing on the application side are
called during the commit phase. Data store operations
will not proceed on any constraint failure.
Designing for concurrency:
Data
store is designed to scale on multi core processors. Multiple
operations on the data store can proceed in parallel if the objects
being accessed are in disjoint relationship collections.
Data store will implement locking at different granularities to parallelize the access.
Persistence:
Some
times objects stored in
the data store might need persistency to avoid resync or relearning the
state from other nodes or for different reaosons. Applications can turn
on
persistency on the objects if
they want persistency. A nearly consistent persistence model is used
rather than absolute consistency. Absolute consistency is costly in
nature, as every object being modified should be written to file system
and then only can be committed in data store. we implement near
consistent persistency which works decent.
Schema definition language:
A
schema language based loosely on object definition language is used to
specify the schema of the data store. Schema langauge will provide
primitives to define classes, relationships and methods. Language also
provides support for direct inclusion of C/C++ code and header files in
the schema file. Schema file is compiled by the schema compiler
and will generate C++ data type definitions and assosciated API calls
to be used by the applications. Applications can include the generated
header files and use the data types emitted by the schema compiler.
schema file ---------------> .h, .cc files ------------------> Application/Datastore plugins
odl compiler
gcc compiler
More detailed explanation and a real life example from atm configuration can be found here
Open issues:
Few things are not clear at this stage
i. Application programming interface to the data store.
ii. Effort involved in defining a new relationships.
iii. What commit protocol can be used for transaction and its performance impact.